[Machine Learning] 더 빠르게, 더 정확하게
데이터 전처리
데이터 전처리는 주어진 데이터를 그대로 사용하지 않고,
좀 가공해서 목적에 맞게 더 좋은 형태로 변형해주는 것입니다.
Feature Scaling
Feature Scaling은 입력 변수들의 크기를 조정해서 일점 범위 내에 떨어지도록 바꿔주는 것입니다.
예를 들어 연봉이랑 나이라는 입력 변수가 있다고 하겠습니다.
사람의 연봉은 몇천만원인것에 비해 사람의 나이는 몇십살밖에 안됩니다.
이렇게 너무 차이가 나는 게 모델 학습에 방해가 될 수 있기 때문에
Feature Scaling을 해서 입력 변수의 크기가 모두 일정 범위 내에 들어오도록 변형해주는 것입니다.
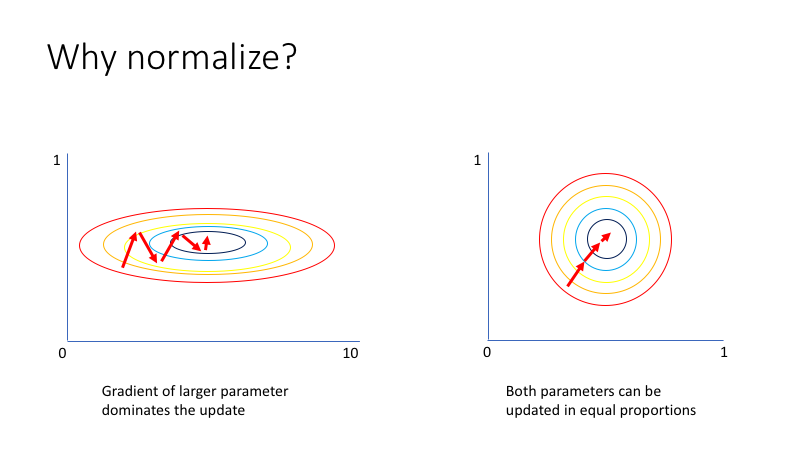
Feature Scaling은 경사 하강법이 더 빨리 수행되도록 도와줍니다.
그 이유는 아래 사진을 참고하세요. 이미지 출처
Feature Scaling을 하는 방법은 여러가지가 있는데,
이번에는 min-max normalization과 표준화(standardization)에 대해 알아보겠습니다.
min-max algorithm
min-max algorithm은 데이터의 최솟값, 최댓값을 이용해서 데이터의 크기를 0과 1사이로 바꿔줍니다.
예를 들어, 아래와 같은 데이터가 있다고 하겠습니다.
| 키 (cm) |
|---|
| 180 |
| 170 |
| 140 |
| 210 |
| 160 |
가장 작은 값과 큰 값은 각각 210과 140입니다.
이 두 값의 차이는 70이 됩니다.
그 다음, 모든 행에서 최솟값인 140을 빼고 각 행을 최댓값과 최솟값의 차이인 70으로 나눠줍니다.
그럼, 아래와 같은 데이터로 변형되게 됩니다.
| 키 (cm) |
|---|
| 0.57 |
| 0.43 |
| 0 |
| 1 |
| 0.29 |
이를 일반화하면 아래와 같은 식으로 표현가능합니다.
\[ \displaystyle x_{new} = \frac{x_{old} - x_{min}}{x_{max} - x_{min}} \]
표준화 (standardization)
표준화는 데이터를 일정한 크기의 숫자들로 scaling 해주는 것입니다.
각 데이터에 평균값을 빼준 후 그 값을 표준 편차로 나눠주면 됩니다.
수식으로 나타내면 아래와 같습니다.
\[ \displaystyle x_{new} = \frac{x_{old} - \mu}{\sigma} \]
scikit-learn으로 normalization 해보기
scikit-learn으로 standardization 해보기
One-hot Encoding
머신 러닝에 사용되는 데이터는 크게 두 가지인데,
하나는 수치형 데이터, 하나는 범주형 데이터입니다.
많은 머신 러닝 알고리즘은 인풋 데이터가 수치형 데이터여야합니다.
범주형 데이터가 있을 땐 어떻게 해야 할까요?
바로 범주형 데이터를 수치형 데이터로 바꿔주면 됩니다.
예를 들어 혈액형을 수치형 데이터로 바꿔준다고 하겠습니다.
A형은 1, AB형은 2, B형은 3, O형은 4라고 한다면 혈액형이 숫자 값을 갖게 할 수 있습니다.
하지만 이렇게 하면 혈액형에 원치 않는 크고 작음이 생겨버립니다.
머신 러닝은 이런 엉뚱한 관계에 대해서도 학습하기 때문에 학습에 방해가 될 수 있습니다.
따라서 머신 러닝에서 범주형 데이터를 수치형 데이터로 바꿔줄 때에는 이 방법을 사용하지 않고
One-hot Encoding 이라는 방법을 사용합니다.
One-hot Encoding은 각 카테고리를 하나의 새로운 열로 만들어주는 방법입니다.
예를 들어 아래와 같은 데이터가 있다고 하겠습니다.
| 혈액형 | 나이 |
|---|---|
| A | 9 |
| AB | 40 |
| B | 35 |
| O | 20 |
One-hot Encoding을 하면 아래와 같이 바뀝니다.
| A형 | AB형 | B형 | O형 | 나이 |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 9 |
| 0 | 1 | 0 | 0 | 40 |
| 0 | 0 | 1 | 0 | 35 |
| 0 | 0 | 0 | 1 | 20 |
이제 이 열들은 0과 1의 두가지 값만 생기기 때문에
범주형 데이터에 크고 작은 관계가 생기는 것을 방지할 수 있습니다.
Leave a comment