[SQL DB] 데이터 조회로 기본 다지기
1. SELECT와 WHERE
이번에는 테이블 안에서 데이터를 찾아보자.
먼저, 아래의 쿼리문을 분석해보자.
SELECT * FROM dbname.tablename;
위의 쿼리문을 실행하면 아래와 같은 화면이 나온다.
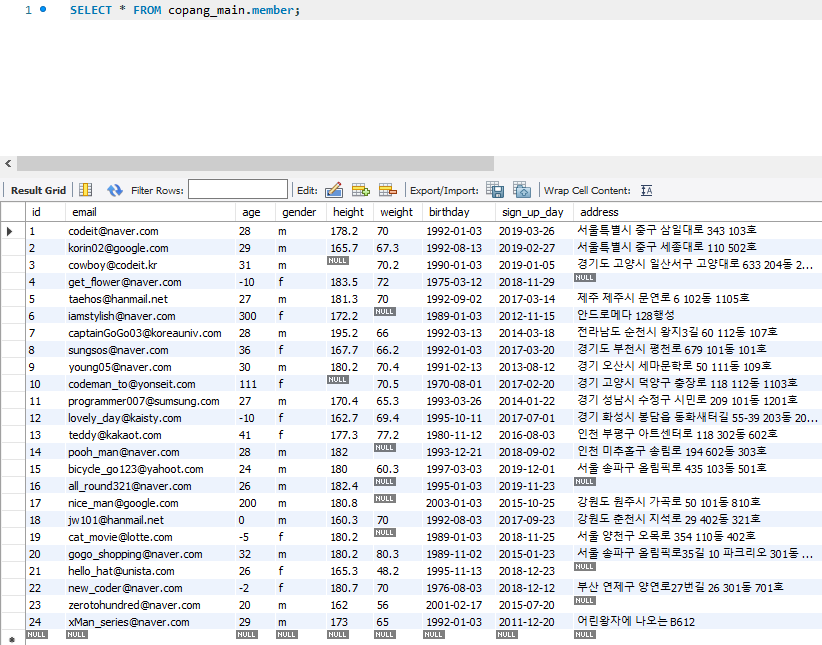
하나하나 뜯어서 보면,
SELECT: 테이블의 데이터를 조회할 때 사용하는 구문
*: 공식 명칭은 asterisk, 각 row의 모든 column들을 보여달라는 뜻
FROM dbname.tablename: 해당 데이터베이스에서 해당 테이블로부터 데이터를 가져온다는 뜻
이번에는 각 row의 모든 column 말고 특정 column을 지정해서 가져오려면 아래와 같이 쿼리문을 구성하면 된다.
SELECT column1, column2, ... FROM dbname.tablename;
나는 email, age, address column을 가져와보겠다.
결과는 아래와 같다.
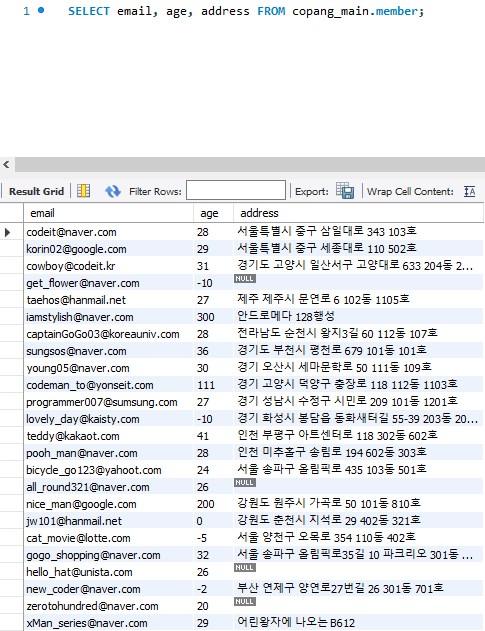
여기까지가 column을 선택해서 데이터를 가져오는 방법이었고,
이제 row를 선택해서 데이터를 가져와보자.
SELECT column1, column2, ... FROM dbname.tablename WHERE column = value;
WHERE: 특정 조건을 만족하는 row들만 조회하려고 할 때 사용
2. SQL 작성 형식
- SQL문 끝에는 항상 세미콜론을 써줘야 한다.
- SQL문 안에는 공백이나 개행 등을 자유롭게 넣을 수 있다.
그러니까, 아래처럼 SQL문을 작성할 수 있다는 말이다.
이런 성질을 이용해서 유연하게 가독성을 높이는 것이 좋은 방법이다.SELECT * FROM ~~ WHERE ~~~; - SQL문을 작성할 때에, MySQL에 기본적으로 내장된 키워드들(예약어 라고 한다.)은 대문자로 써주는 것이 관례이다.
- 앞에서는 어떤 테이블을 특정하기 위해서 dbname.tablename방식의 SQL문을 사용했는데,
항상 그렇게 할 필요는 없고 아래와 같이 사용할 수도 있다.
서로 다른 DB에 같은 이름의 table이 존재할 수 있기 때문에 앞서 보인 것처럼 쓰는게 좋은 방법이니 상황에 따라 유연하게 사용하자.USE dbname; SELECT * FROM tablename;
3. 조건을 나타내는 다양한 방법
# 값이 같은지 확인
SELECT * FROM dbname.tablename WHERE col = val;
# 값이 다른지 확인, != 대신 <>도 사용 가능하다.
SELECT * FROM dbname.tablename WHERE col != val;
# col의 값이 val보다 크거나 같은지 확인, 마찬가지로 >, <=, <도 사용 가능하다.
SELECT * FROM dbname.tablename WHERE col >= val;
# DATE 타입에 대해서도 부등호 사용이 가능하다. 아래의 경우에는 col이 2019-01-01 이후인지 확인
SELECT * FROM dbname.tablename WHERE col > '2019-01-01';
# col의 값이 [val1, val2]에 포함되는지 확인
SELECT * FROM dbname.tablename WHERE col BETWEEN val1 AND val2;
# DATE 타입에 대해서도 BETWEEN 사용이 가능한데, 아래의 경우엔 col이 2019년 이내인지 확인
SELECT * FROM dbname.tablename WHERE col BETWEEN '2019-01-01' AND '2019-12-31';
# col의 값이 [val1, val2]에 포함되지 않는지 확인
SELECT * FROM dbname.tablename WHERE col NOT BETWEEN val1 AND val2;
# col의 값이 val1, val2, ... 중에 있는지 확인
SELECT * FROM dbname.tablename WHERE col IN (val1, val2, ...)
4. 문자열 패턴 매칭 조건
위에서 보였던 테이블에서 주소가 서울인 사람만 골라내려면 문자열 패턴 매칭을 이용해야 한다.
SELECT * FROM copang_main.member WHERE address LIKE '서울%';
이렇게 쿼리문을 작성하면, copang_main.member에서 주소가 서울로 시작하고 뒤에는 임의의 문자열이 오는 문자열을 나타낸다.
즉, 서울로 시작하는 모든 문자열을 나타낸다.
SELECT * FROM copang_main.member WHERE address LIKE '%고양시%';
이렇게 작성하면, 고양시 앞뒤로 임의의 문자열이 오는 문자열을 나타낸다.
즉, 고양시가 포함된 모든 문자열을 나타낸다.
위에서 봤던 % 외에도 _ 도 문자열 패턴에 쓰인다.
언더바 하나는 문자 하나를 나타낸다.
SELECT * FROM copang_main.member WHERE address LIKE '고_시%';
위와 같이 작성하면, ‘고’ 로 시작하고 임의의 한글자가 온 후 ‘시’가 온 후에 임의의 문자열이 오는 문자열을 나타낸다.
5. DATE 데이터 타입 관련 함수
DATE 데이터 타입에서 연, 월, 일을 추출하기
SELECT * FROM dbname.tablename WHERE YEAR(col) = '1998';
SELECT * FROM dbname.tablename WHERE MONTH(col) IN (6, 7, 8);
SELECT * FROM dbname.tablename WHERE DAYOFMONTH(col) BETWEEN 15 AND 31;
날짜 간의 차이 구하기
# DATEDIFF(날짜1, 날짜2) 를 사용하면 날짜1 - 날짜2를 해서 그 차이 일수를 알려준다.
# 아래의 코드는 2019-01-01 기준으로 365일이 지났는지 확인한다.
SELECT * FROM dbname.tablename WHERE DATEDIFF(col, '2019-01-01') <= 365;
오늘 날짜 구하기
# CURDATE()는 오늘 날짜를 가져온다.
# 아래의 코드는 col 이후로 365일이 지났는지 확인한다.
SELECT * FROM dbname.tablename WHERE DATEDIFF(CURDATE(), col) <= 365;
날짜 더하기 빼기
# 날짜를 더하는 함수는 DATE_ADD 함수이다.
# 아래의 코드는 오늘 날짜 기준으로 300일 이후의 날짜를 구한다.
SELECT DATE_ADD(CURDATE(), INTERVAL 300 DAY);
# 날짜를 빼는 함수는 DATE_SUB 함수이다.
# 아래의 코드는 오늘 날짜 기준으로 250일 이전의 날짜를 구한다.
SELECT DATE_SUB(CURDATE(), INTERVAL 250 DAY);
UNIX Timestamp 값
날짜뿐만 아니라 시간까지 포함하는 컬럼이라면 DATETIME이라는 데이터 타입을 사용해야 하는데,
DATETIME 타입의 컬럼에는 보통 ‘2021-11-04 01:13:59’ 이런 식으로 값들이 저장되어 있다.
어떤 테이블에는 1553526000 이런 식으로 아주 큰 숫자값이 적혀있는 경우들이 많은데,
이 또한 날짜와 시간을 나타내는 값인데, 이런 형식의 날짜기간 값을 UNIX Timestamp라고 한다.
UNIX Timestamp는 특정 날짜의 특정 시간을, 1970년 1월 1일을 기준으로 총 몇 초가 지났는지로 나타낸 값이다.
# UNIX_TIMESTAMP 함수는 DATE타입의 값을 인자로 넣어주면 그것을 UNIX Timestamp 값으로 바꿔준다.
SELECT UNIX_TIMESTAMP(CURDATE());
# FROM_UNIXTIME 함수로 UNIX Timestamp 값을 사람이 읽을 수 있는 날짜 형태로 바꿔서 볼 수도 있다.
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(CURDATE()));
7. 여러 개의 조건 걸기
한 가지 조건 뿐만 아니라 여러가지 조건을 한번에 쓰고 싶을 수도 있다.
그럴 경우에는 AND 또는 OR 키워드를 사용하면 된다.
SELECT * FROM dbname.tablename WHERE 조건1 AND 조건2;
SELECT * FROM dbname.tablename WHERE 조건1 OR 조건2;
# 아래와 같이 섞어서 쓸 수도 있다.
SELECT * FROM dbname.tablename WHERE (조건1 AND 조건2) OR (조건3 AND 조건4);
# 그런데, AND와 OR을 섞어 쓸 때에는 AND가 OR보다 우선순위가 높다는 것을 주의해야 한다.
# 그러니까, 아래 두 줄은 같은 의미이지만,
SELECT * FROM dbname.tablename WHERE 조건1 AND 조건2 OR 조건3 AND 조건4;
SELECT * FROM dbname.tablename WHERE (조건1 AND 조건2) OR (조건3 AND 조건4);
# 이 두줄은 다른 의미라는 것이다.
SELECT * FROM dbname.tablename WHERE 조건1 OR 조건2 AND 조건3 OR 조건4; # ...ㄱ
SELECT * FROM dbname.tablename WHERE (조건1 OR 조건2) AND (조건3 OR 조건4);
# 위에서 ㄱ 표시를 해둔 줄과 같은 의미인 SQL문을 만들어본다면 아래와 같이 된다.
SELECT * FROM dbname.tablename WHERE 조건1 OR (조건2 AND 조건3) OR 조건4;
# 이것처럼 실제 원하는 바와 다르게 해석될 수 있으므로 OR과 AND를 섞어 쓸 때에는 주의하도록 하고,
# 될 수 있으면 우선순위를 신경쓰기보다는 실수를 줄이기 위해 각 조건에 괄호를 씌워주는 것이 좋다.
8. 문자열 패턴 매칭 조건 사용 시 주의할 점
%가 포함된 모든 문자열을 찾으려고 한다고 해보자.
아래와 같이 작성하면 원하는 대로 작동할까?
SELECT * FROM dbname.tablename WHERE col LIKE '%%%';
원하는 대로 작동하지 않고 어떠한 필터링도 되지 않은 채 모든 row들이 나오게 될 것이다.
그 이유는 위에서 쓴 모든 % 들이 문자로서의 %가 아니라 LIKE에서 쓰이는 표현식으로 간주되었기 때문인데,
이런 표현식 말고 문자로서의 % 를 써주려면 % 앞에 \ 을 붙여주면 된다.
아래처럼 작성한다면 원하는 대로 작동한다.
SELECT * FROM dbname.tablename WHERE col LIKE '%\%%';
이 외에도 %, _, ‘, “ 같은 문자들을 직접 찾으려면 앞에 \ 을 붙여주면 된다.
테이블 설정의 Table collation이 case-insensitive(ci)로 설정되어 있다면 문자열 비교 시 대소문자 구분이 안된다.
따라서, 설정에 관계없이 대소문자 구분을 할 수 있는 방법이 필요하다.
정확히 소문자 a가 포함된 문자열을 나타내려고 한다면 아래와 같이 작성하면 된다.
SELECT * FROM dbname.tablename WHERE col LIKE BINARY '%a%';
LIKE 뒤에 BINARY를 붙인 게 보일텐데,
a와 A는 같은 알파벳이긴 하지만 컴퓨터에서 0과 1의 조합으로 저장될 때 다른 값으로 저장된다.
BINARY를 붙인 것은 알파벳 뿐만 아니라 0과 1 수준까지 문자열 비교를 하라는 뜻이다.
따라서 대소문자를 구별하고 싶다면 BINARY를 잘 활용해보자.
9. 데이터 정렬해서 보기
이번에는 데이터를 정렬해보자.
어떤 col에 대해서 정렬을 하고싶다면 다음과 같이 SQL문을 작성하면 된다.
SELECT * FROM dbname.tablename ORDER BY col; # 기본적으로 오름차순 정렬을 해주지만, 실수를 방지하기 위해
SELECT * FROM dbname.tablename ORDER BY col ASC; # 이렇게 작성해주는게 좋다.
SELECT * FROM dbname.tablename ORDER BY col DESC; # 내림차순 정렬은 DESC를 붙여주면 된다.
어떤 조건을 건 후 조건에 부합하는 row들에 대해서만 정렬을 하고 싶다면 다음과 같이 작성해주면 된다.
SELECT * FROM dbname.tablename
WHERE 조건
ORDER BY col ASC;
이렇게 쓸 때, 각 절의 작성 순서는 지켜지지 않으면 에러가 발생하므로 엄격하게 지켜줘야 한다.
MySQL에서 SELECT문 내의 각 절들 간 작성 순서가 정확히 알고 싶다면 여기를 참고하자.
이렇게 한 가지 col에 대해서 정렬을 할 수 있는데,
여러 col에 대해서 정렬을 하고 싶을 수도 있다.
그럴 경우엔 아래와 같이 작성해주면 된다.
SELECT * FROM dbname.tablename
ORDER BY col1 DESC, col2 ASC; # col1 기준으로 우선 내림차순 정렬 후 col1이 같은 row들은 다시 col2 기준으로 오름차순 정렬
# 즉, 먼저 쓴 컬럼을 우선순위로 해서 정렬한다.
10. 데이터 타입에 따른 정렬 기준
네 개의 수 3, 20, 100이 있다고 하자.
이 수들의 데이터 타입이 INT라고 한다면, 오름차순 정렬을 했을 떄 3, 20, 100 순서로 정렬된다.
그런데, 데이터 타입이 TEXT라고 한다면, 오름차순 정렬을 했을 때 100, 20, 3의 순서로 정렬된다.
이런 일이 일어나는 것은
INT 타입의 값은 숫자의 대소를 기준으로 정렬이 되지만,
TEXT 타입의 값은 숫자의 대소가 아니라 한 문자, 한 문자씩 그 문자 순서를 비교해서 정렬이 된다.
따라서, 숫자값이 담긴 컬럼을 기준으로 정렬할 때에는 데이터타입이 TEXT는 아닌지 잘 살펴봐야 한다.
만약, 데이터타입이 TEXT인데 숫자의 대소의 기준으로 정렬을 하고싶다면 CAST 라는 함수를 써야한다.
CAST 함수는 아래와 같이 사용할 수 있다.
SELECT * FROM dbname.tablename ORDER BY CAST(col AS signed) ASC; # col의 데이터 타입을 일시적으로 signed로 하여 정렬
signed는 양수와 음수를 포함한 모든 정수를 나타낼 수 있는 데이터 타입이다.
0 이상의 모든 정수를 표현하고 싶다면 unsigned를,
소수점이 있는 수를 표현하고 싶다면 decimal을 사용하면 된다.
11. 데이터 일부만 추려보기
앞에서는 row들을 정렬해서 가져오는 걸 해봤는데,
이번에는 그 결과 중 일부만 추려서 한 번 가져와보자.
SELECT * FROM dbname.tablename
ORDER BY col DESC # col 기준으로 내림차순 정렬한 후
LIMIT 10; # 상단 10개 row만 가져온다.
위와 같이 LIMIT을 이용하면 된다.
만약 9번째 row로부터 2개의 row만 가져오려고 한다면 아래와 같이 작성하면 된다.
SELECT * FROM dbname.tablename
ORDER BY col DESC
LIMIT 8, 2;
Leave a comment